
Big Data im US-Wahlkampf
Big Data ist spätestens seit der Nacht vom 8. auf den 9. November 2016 in aller Munde. Denn in dieser Nacht hatte Donald Trump völlig unerwartet die Präsidentschaftswahl für sich entschieden. Schnell vermehrten sich Gerüchte zur Manipulation über Social Media. Darunter ein Artikel, der sich in den deutschsprachigen Netzwerken wie ein Lauffeuer verbreitete: Unter dem reißerischen Titel „Ich habe nur gezeigt, dass es die Bombe gibt“ portraitierte die österreichische Zeitschrift „Das Magazin“ den Psychologen Michal Kosinski. Der Wissenschaftler habe eine Methode entwickelt, mit Big Data das Verhalten von Menschen in Echtzeit zu analysieren. Ferner sogar deren Persönlichkeit zu vermessen. Dieses hochgefährliche Wissen sei für die US-Wahl missbraucht worden, sinnbildlich sei dadurch die Bombe geplatzt.
Fragestellungen zu Big Data
Im folgenden Artikel möchte ich mich deshalb der Frage widmen, wie Big Data unsere Gesellschaft verändern könnte. Dabei soll zum einen diskutiert werden, wie groß die Gefahr ist, dass zukünftig Wähler durch Big Data beeinflusst werden (1). Ein zweiter Gesichtspunkt ist die Frage, welchen Effekt Big Data auf unser Gesellschaftssystem haben könnte (2).
Big Data-Modell von Kosinski
Um die erste Frage zu diskutieren, muss zunächst das Modell von Kosinski, das auf einem Ansatz aus der Psychometrie beruht, vorgestellt werden. Der Forscher ermittelt anhand der fünf OCEAN-Faktoren die Persönlichkeitsstrukturen eines Menschen (siehe Grafik). Laut dem Artikel habe Kosinski dieses Modell auf Facebook übertragen und nachgewiesen, dass man anhand weniger Likes präzise Aussagen über eine Person treffen kann. Grund für die hohe Aussagekraft sei ein Abgleich der Daten, die überall im Netz verfügbar seien. Möchte man nun gezielt ein bestimmtes Publikum erreichen, sei dieser Ansatz deutlich effektiver als herkömmliche Maßnahmen aus dem Marketing.
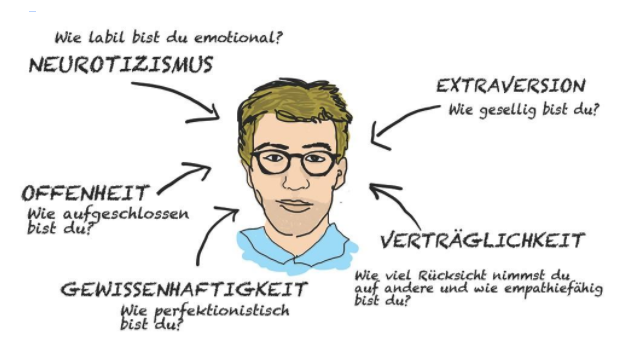
OCEAN-Faktoren zur Analyse von Persönlichkeitsstrukturen
Die Funktionsweise von BigData-Analysen
Was an der Aussage stimmt ist die Tatsache, dass sich Big Data Ansätze von traditionellen Marketinganalysen durch ihre Komplexität unterscheiden. Denn manche Fragestellungen sind so vielseitig, dass sie von herkömmlichen SQL-Datenbanken nicht mehr beantwortet werden können. Gleichzeitig können mit Big Data algorithmenbasierte Vorhersagen getroffen werden – die Predictive Analytics. Zusammenfassend wird Big Data deshalb als eine unüberschaubar große Menge an Daten (Volume) definiert, die sich in Echtzeit verändert (Velocity) und sich sehr schnell verbreiten kann (Virality). Die Daten stammen aus unterschiedlichen Quellen (Viscosity) und können daher in jedem erdenklichen Format auftreten (Variety).
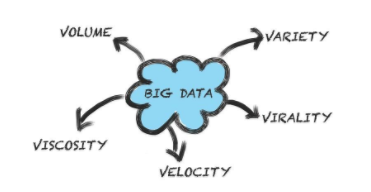
Big Data Analytics
Um aus dieser Daten- und Formvielfalt Informationen zu gewinnen, professionalisieren sich die Technologien zur Datenauswertung zunehmend. Bekannte Anbieter von Big Data Lösungen sind beispielsweise Hadoop, Cloudera und Mongo DB. Während sich Hadoop bei komplexen und aufwändigen Analysen anbietet, ist Cloudera besonders gut geeignet für Echtzeitabfragen. Mongo DB versteht sich selbst als Allzweckdatenbank.
Big Data als Einflussnehmer
Wie die Anzahl an Service Providern verdeutlicht, ist es technisch längst möglich, Kosinskis Methode im großen Stil durchzuführen. Während das Magazin den Wissenschaftler als tragischen Held beschreibt, der die Welt vor den Gefahren seiner Forschung schützen wollte, wird ebenso ein Sündenbock geliefert: Ein Forscherkollege habe die Ergebnisse verkauft, sodass das Wissen am Ende bei dem Politmarketing-Unternehmen Cambridge Analytica landete. Pünktlich zum Wahlsieg Trumps outete sich das Big Data Unternehmen, sowohl die US-Wahl als auch den Brexit beeinflusst zu haben.
Dass die Firma dazu in der Lage ist, impliziert der Artikel am Paradebeispiel Ted Cruz. So sei es auf die Mikro-Targeting Vorgehensweise des Unternehmens zurückzuführen, dass das unbeschriebene Blatt Cruz zum Kandidaten für das höchste Amt in den USA aufsteigen konnte. Doch warum hatte Ted Cruz‘ Team dann mitten im Wahlkampf die Zusammenarbeit mit Cambridge Analytica beendet? Darauf geht der Artikel nicht ein. Ebenso wenig auf die Frage, ob es womöglich andere Gründe geben könnte, warum die Big Data Firma plötzlich die Seiten wechselte, um den Republikaner mit den besseren Gewinnchancen, Trump, zu unterstützen.
Eines ist jedenfalls klar: Die Aussagen sind mit Vorsicht zu genießen. Denn hinter der gewonnenen Publicity des Unternehmens steckt ein Marketingapparat. Dass Cambridge Analytica am Ende dem Gewinner-Team angehörte, hatte vor allem dazu beigetragen, das Image zu verbessern und die Effektivität der Big Data Analyse mit dem Erfolgsbeispiel Trump zu illustrieren. Vermutlich lief alles nach Plan. So hatte die Mutterfirma des Unternehmens, die SCL Group, der Washington Post zufolge bereits neue Verträge mit der US-Regierung im Visier. Gleichzeitig besitzt das Unternehmen einen guten Draht zum inneren Kreis des Weißen Hauses – vor allem zu ihrem ehemaligen Aufsichtsrat und bis vor kurzem Chef-Strategen Stephen Bannon. In diesem Zusammenhang muss erwähnt werden, dass es nicht erst seit Cambridge Analytica umfassende Datenanalysen im US-Wahlkampf gibt. Bereits in früheren Wettkämpfen wie etwa Barack Obamas Wahlkampf im Jahr 2008 stütze man sich auf eine umfassende Datenauswertung. Nicht nur Trump, sondern auch Hilary Clinton hatte ein Digital-Team hinter sich stehen, welches ihre Taktik statistisch berechnete.
Big Data als Zukunftstrend
Außerdem sollte sich unser Blick nicht nur auf die USA richten, sondern auch auf Deutschland und Europa. Denn Big Data ist auch hier in sämtlichen Bereichen der Gesellschaft präsent. Ein möglicher Grund für den Erfolg des Artikels aus Österreich ist die diffuse Angst vor dem Thema. So wird Big Data häufig als mysteriöses Buzzword gebraucht, das einen Zukunftstrend aus den Untiefen des Internets beschreibt. Jedoch wird nicht differenziert, was an dem Thema Datenanalyse wirklich neu ist. Denn auch in Deutschland arbeitet man seit Jahren mit dem Mikro-Targeting – sowohl in der Wirtschaft als auch in der Politik.
Die erste Frage (1) lässt sich also damit beantworten, dass hinter der Verschwörungstheorie die gesellschaftliche Angst vor dem unbekannten Thema Big Data steht. So ist eine zielgruppengerechte, datenbasierte Ansprache ein typisches Instrument, das seit Jahren sowohl im Marketing als auch in der Politik zum Einsatz kommt. Darüber hinaus werden in sozialen Netzwerken sämtliche zielgruppenspezifische Anzeigen gekennzeichnet, sodass man nicht von Manipulation sprechen kann. Denn trotz gekennzeichneter Werbeanzeigen bleiben die Menschen selbstbestimmt und werden nicht dazu gezwungen, ihr Kreuz bei einer bestimmten Partei zu setzen. Gleichzeitig liegt es in der Natur der Werbung, die Zielgruppe von sich überzeugen zu wollen.
Big Data in der Wirtschaft
Um sich der zweiten Frage zu widmen ist es wichtig zu wissen, dass datenbasierte Zukunftsprognosen bereits in vielen Bereichen der Gesellschaft zum Einsatz kommen. Während sie in der Politik unter anderem für Vorhersage von Wahlentscheidungen genutzt werden, gibt es ebenso viele Einsatzmöglichkeiten in der Wirtschaft. Im Produktionssektor ermöglichen es Big Data Prognosen zum Beispiel, die Wahrscheinlichkeit für das Abbrechen bestimmter Lieferketten zu ermitteln, was eine genauere Planung ermöglicht. Ebenso können Unternehmen schneller auf Veränderungen des Marktes reagieren und neue Angebote entwickeln. Branchenübergreifend geht es darum, einen Wettbewerbsvorteil zu erlangen, indem man lernt, aus einer unüberschaubaren Menge an Daten die relevanten Informationen zu erkennen und diese zu nutzen.
In Deutschland sind vor allem Versicherer und die Automobilbranche Vorreiter im Einsatz von Big Data. Laut einer Studie der Bitkom Research nutzten Anfang 2016 bereits 21 Prozent der deutschen Versicherer und Automobilbauer Big Data Analysen – die Tendenz ist steigend. Am Beispiel Versicherung lässt sich erahnen, welche Folgen der Einsatz von Big Data auf ein Gesellschaftssystem haben kann.
Big Data im Gesundheitssystem
Generell steht die Versicherungsbranche von heute unter enormem Druck. Denn Versicherungsnehmer fordern adäquate Angebote, die der digitalisierten Gesellschaft gerecht werden. Neue Themen, wie das autonome Fahren oder das Self-Tracking, verlangen entsprechende Lösungen und bringen das herkömmliche Versicherungsmodell ins Wanken.
Bislang zahlt jeder Versicherungsnehmer – basierend auf dem Solidaritätsprinzip – gemäß seiner finanziellen Möglichkeiten in die Versicherung ein. Im Schadensfall eines Einzelnen kommt die Gruppe für die Kosten auf. Um diese Belastung der Gemeinschaft im Voraus zu planen, errechnet die Versicherung einen ungefähren Bedarf – was ohne fundierte Fakten und Daten kaum denkbar wäre.
Mittlerweile übertreffen jedoch die extern gewonnenen Daten die intern gewonnenen bei Weitem. Gleichzeitig werben Versicherer, wie beispielsweise die Techniker Krankenkasse, mit speziellen Bonusprogrammen für die Verwendung von Fitnesstrackern und Wearables. Dabei verfolgt man das Ziel, die allgemeine Gesundheit in der Bevölkerung zu verbessern, so der Versicherer. Dies würde ebenfalls auf den Grundsatz der Solidarität einzahlen, die in der Versicherung nur funktioniere, wenn genügend gesunde Menschen daran teilnehmen, gibt Dr. Jens Baas, CEO der Techniker Krankenkasse, in einem Interview zu verstehen. Doch was passiert mit den Menschen, deren Daten einen Hinweis darauf geben, dass sie womöglich bald krank werden? Diese Frage bleibt unbeantwortet.
Probleme & Lösungsansätze bei der Verwendung von Big Data im Gesundheitssystem
Während man in der Krankenversicherung noch vor Big Data Analysen zögert, zeigt sich am Beispiel der Munich Re, wie eine Datenabfrage das B2B-Geschäft verändern kann. Als Rückversicherung ist die Munich Re eine Versicherung für Versicherer. Das bedeutet, dass Versicherungen ihr Risiko auf die Munich Re übertragen können. Vor allem hohe Versicherungssummen machen diesen Schritt notwendig. Im Schadensfall muss der Rückversicherer möglichst schnell informiert werden, damit er noch schadensmildernd eingreifen kann.
In der Praxis bereitete die Geschwindigkeit der Informationsweitergabe zwischen den einzelnen Unternehmen oft erhebliche Probleme. Die Lösung versprach der Big Data Ansatz des IT-Service-Providers Empolis. Unabhängig von den eingehenden Schadensmeldungen bei der Munich Re sollte eine Auswertung verschiedenster Nachrichtenquellen Informationen über aufkommende Schäden zwischen 5 und 50 Mio. € liefern. Dabei war es wichtig, die starke Varianz in Bezug auf Verlässlichkeit und Datenqualität zu berücksichtigen. Insgesamt wurden über 4.000 Nachrichtenquellen in Echtzeit nach relevanten Schadensereignissen gefiltert. Neben Nachrichtenfeeds, Onlinemedien und Social Media-Quellen wurden ebenso spezialisierte Datenquellen, wie beispielsweise Quellen des Umweltbundesamtes oder des US National Transportation Savety Board, untersucht. Ein siebenstufiges Wissensmodell identifizierte anschließend die relevanten Nachrichten und ordnete sie mittels Annotation und Semantik bestimmten Ereignissen zu. Die Ergebnisse halfen den Sachbearbeitern dabei, den Prozess zu beschleunigen.
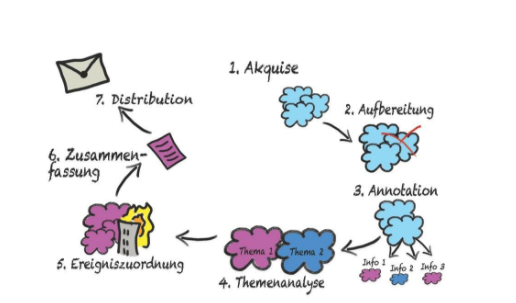
Wissensmodell Big Data
Wie an diesem Beispiel deutlich wird, ist es durchaus denkbar, dass in naher Zukunft solche Analysen auch bei Krankenversicherungen zum Einsatz kommen. Beiträge würden sich dann nicht nur anhand des Einkommens bemessen, sondern vielleicht stärker am Lebensstil der Versicherten ausrichten. Zusätzlich kann man davon ausgehen, dass die Versicherungen neue Angebote und Formate entwickeln werden. Inwiefern das Modell dann noch dem Solidaritätsprinzip entspricht, ist ein offener Diskussionspunkt, der bereits bei der Auffassung von Solidarität beginnt.
Die zweite Frage (2) kann deshalb nur mit der Annahme beantwortet werden, dass sich durch Big Data Analysen klassische Gesellschaftssysteme verändern können. Im Gesundheitssystem werden sich künftige Debatten darauf fokussieren, inwiefern es gerecht ist, ungesund lebenden Versicherungsnehmen höhere Beiträge zu berechnen, wenn sie der Allgemeinheit schneller zur Last fallen könnten.
Big Data: Der gläserne Konsument
Zusammenfassend lässt sich schlussfolgern, dass Big Data kein „Hexenwerk“ ist, das es erst seit dem Wahlsieg Trumps gibt. Probleme, denen man sich künftig im Bereich der politischen Meinungsbildung stellen muss, sind sogenannte „Fake News“. Um zu vermeiden, dass bestimmte Personengruppen in ihrer eigenen politischen Realität leben, sind sowohl die Betreiber sozialer Netzwerke wie auch der Gesetzgeber gefordert. Gleichzeitig muss diskutiert werden, inwiefern personenbezogene Big Data Analysen mit dem Prinzip der Zweckbindung und Transparenz der EU Datenschutzverordnung (Art. 5) vereinbar wären. Dabei ist zu berücksichtigen, dass ein vollständiges Verbot von Big Data Analysen auch ein wirtschaftliches Risiko bedeutet. Denn Predictive Analytics und ein präzises Customer Insight werden für Unternehmen zunehmend essentiell, um im Wettbewerb zu bestehen. Während unsere Gesellschaft von immer individuelleren Angeboten profitieren wird ist die Kehrseite der Medaille, dass wir zunehmend gläsern werden. Doch sind wir das nicht sowieso schon?